The agri-food supply chain requires accurate forecasting of its production performance since failure affects a vital population need. Maize, rice, and wheat are the three primary cereals consumed globally. However, a key distinction in the industrial processing of maize compared to rice and wheat is dry and wet milling. Dry milling of maize yields primary products such as semolina and various flours, while wet milling primarily generates starch, gluten, and feed. Wet maize is highly vulnerable to fungal growth and insect pests. Therefore, it is necessary to minimise storage duration before processing. Ideally, grains should be incorporated into the processing chain immediately after harvesting, so scheduling harvest activities is vital for achieving optimal results.
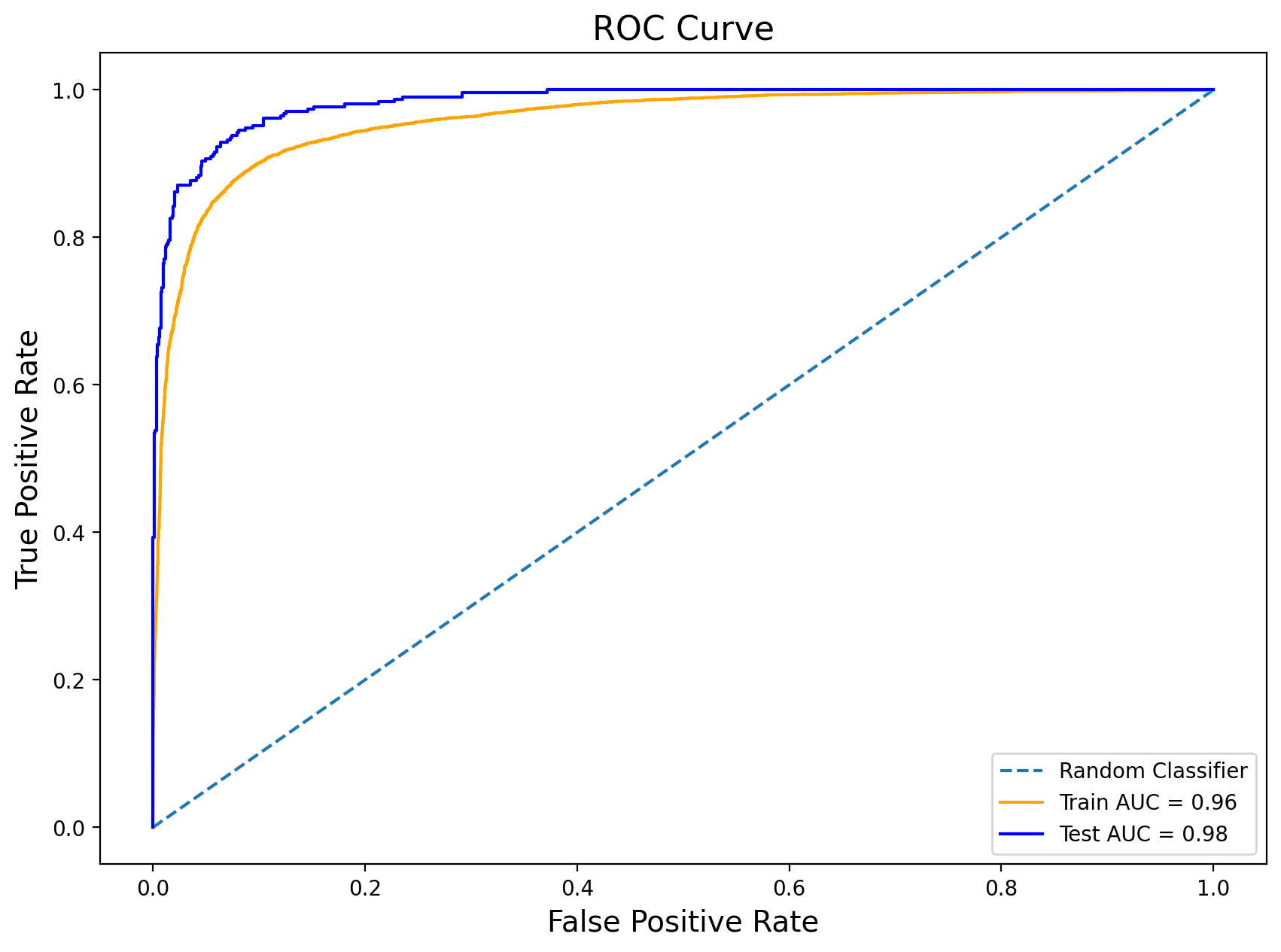
Figure 3: ROC CURVE in one of the folds
This paper developed a predictive model to determine the optimal harvest time in maize plots using the Normalised Difference Vegetation Index (NDVI) and climatological data. These variables were oversampled and used to train various models: Random Forest (RF), Gradient Boosting Machine (GBM), Light Gradient Boosting Machine (LGBM), Extreme Gradient Boosting Machine (XGBoost), CatBoost, and Support Vector Machine (SVM). The study utilized high-resolution satellite imagery from the Sentinel-2 satellite and meteorological data provided by the state meteorological agency of Spain. The NDVI values, indicative of plant health and vitality, were processed to remove outliers caused by meteorological conditions during data acquisition. The model development focused on analyzing the effect of climatic variables such as atmospheric pressure, mean temperature, and precipitation on maize yield. Bayesian optimisation was used to find the best hyperparameters, and Shapley values, a method for assigning the contribution of each feature to the prediction, were used to identify the variables that significantly influence prediction in each model instance.
The Gradient Boosting Machine (GBM) showed the best classification and generalization ability results. The research demonstrated that a combination of NDVI and climatic data could predict the harvest date with an accuracy of 92.1% and an Area Under the Curve (AUC) of 0.935; these results indicate the potential of using machine learning models for efficient agricultural planning and decision-making.
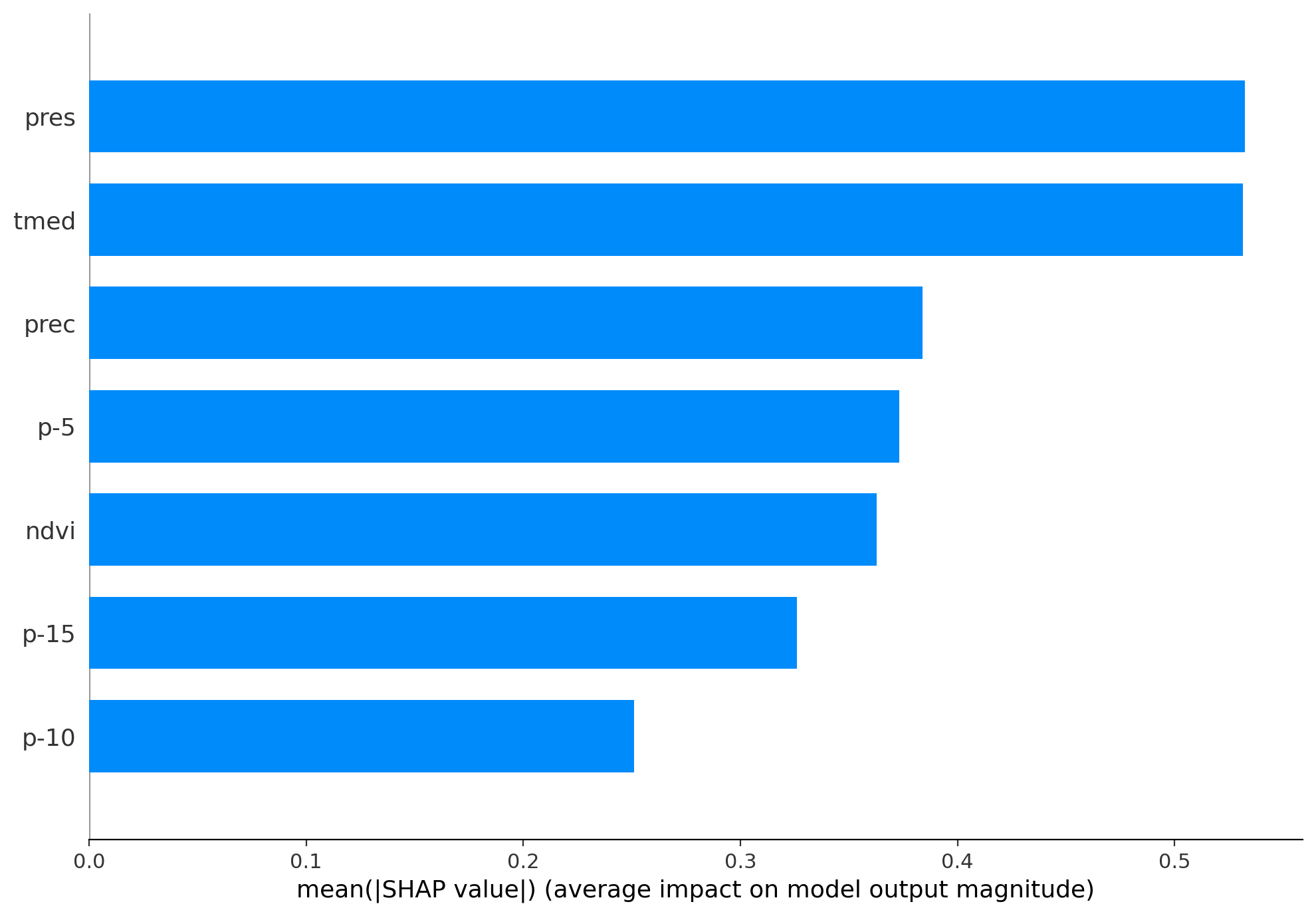
Figure 4. Mean SHAP values for variables that influence maize prediction in random fold selected
Finally, the study concludes that advanced predictive models can significantly enhance the efficiency of maize harvesting operations, providing valuable insights for farmers and processing companies. In the Future, research will focus on extending the dataset and exploring the application of these models to other crops, aiming to improve agricultural productivity and sustainability.
Evaluating the efficiency of NDVI and climatic data in maize harvest prediction using machine learning. . M.E. SUAZA-MEDINA, J. LAGUNA, R. BÉJAR, F.J. ZARAZAGA-SORIA, J. LACASTA. International Journal of Digital Earth, vol. 17(1), 2024.